
RAG Chunking Strategies:
Visual Guide to Finding Your Optimal Chunk Size
1Why Chunking is Underrated in RAG
Companies are projected to spend around $650 billion
on AI in 2026 — the single largest technology investment in history. Teams are benchmarking embedding models,
debating vector databases, and fine-tuning prompts. However, a major decision that determines whether their RAG system will actually work only gets about 15
minutes of attention.
That decision is chunking: how you split documents before they enter your retrieval pipeline.
The $650 billion decision making trap
It sounds like plumbing. A preprocessing detail you configure once and never think about again. It is the opposite of that. According to production deployment data published by Prem AI, roughly 80% of RAG failures trace back to the ingestion and chunking layer — not the LLM, not the embedding model, not the vector database. The retrieval is quietly returning the wrong context every third query, and teams spend weeks tuning prompts and swapping models trying to fix a problem that lives upstream.
What "wrong chunks" actually cost you
RAG failure can be deceptive. Your system doesn't crash. It doesn't give critical errors. It just gives answers that are "almost" right — a refund policy combined with an HR
FAQ, an API reference that cuts off mid-block, or service call chat logs (nightmare!). The LLM outputs whatever context you hand it, and if that context is garbage,
the output is polished garbage. You know the saying, "Garbage in, garbage out."
Take a look at a study done by Vecta which shows the popular strategy is not always the best!
One startup founder documented this exact progression publicly: their support agent went from 52% retrieval accuracy with naive 1,000-token chunks, to 89% accuracy simply by switching to markdown-aware splitting — same model, same database, same prompts. The only thing that changed was where the text was cut.
What this guide covers
This is the companion article to the RAG Chunking Playground, a free interactive tool that lets you paste any document and compare six chunking strategies side-by-side. Over the next sections, we'll cover: Where chunking sits in the RAG pipeline and why it's the highest-leverage optimization. The six major strategies — fixed-size, recursive, sentence, markdown, regex, and semantic — with visual breakdowns of how each one handles the same text. What the 2026 benchmark data actually shows about optimal chunk sizes. A head-to-head comparison of semantic vs. recursive chunking. When overlap helps (and the surprising cases where it doesn't). A decision framework for matching strategy to document type. And how to evaluate chunk quality before it ever reaches your users. Every claim in this article can be tested in the playground. That's the point — chunking isn't something you should take on faith.
2What Chunking Actually Does in a RAG Pipeline
How chunking fits in the retrieval pipeline
Before diving into specific strategies, it helps to see where chunking sits in teh retrieval process. Let's first understnd this before and after the split. A RAG system has five stages. Documents come in. They get split into chunks. Each chunk gets converted into a vector embedding. Those embeddings get stored in a vector database. When a user asks a question, the system embeds the query, retrieves the most relevant chunks, and hands them to the LLM as context for an answer.
Chunking is stage two — and it's the last point where you have full control over what the LLM will see. Everything downstream is automated: the embedding model transforms your chunks into vectors, the vector database then ranks them by how similar they are, and the LLM whatever context it receives. If the chunks are garbage, then every subsequent stage inherits that as well.
Why you can't just skip chunking
Many people ask this question: if models now support massive context windows, why not stuff the entire document in and let the LLM figure it out? Chroma's context rot research tested this across 18 models — including GPT-4.1, Claude 4, and Gemini 2.5 — and found that retrieval performance degrades as context length increases, even on straightforward tasks. A separate January 2026 analysis identified a "context cliff" around 2,500 tokens where response quality drops sharply.
Longer context doesn't mean better answers. It means more noise for the model to filter through. Strategic RAG chunking exists to solve this exact problem: give the model concise, relevant passages instead of making it search through thousands of loosely related tokens.
INTERACTIVE: THE 5-STAGE RAG PIPELINE
The two failure modes
Every chunking problem falls into one of two buckets.
Chunks that are too small lose context — the retriever finds a fragment but the LLM doesn't have enough surrounding information to generate a useful answer.
Chunks that are too large dilute relevance — the right answer is buried in a wall of unrelated text, and the LLM either misses it or hallucinates something that isn't there. The practical sweet spot, validated across multiple benchmarks, falls between 256 and 512 tokens with 10–20% overlap. The next section breaks down each of the six strategies that navigate between these two extremes — and how your choice affects what the LLM ultimately sees.
3 The 6 Chunking Strategies Explained
Not all RAG chunking strategies are interchangeable. Each one makes a different tradeoff between speed, semantic coherence, and implementation complexity. The six strategies below cover the full spectrum — from the simplest character-count split to embedding-based semantic detection. These are the same six strategies you can test side-by-side in the RAG Chunking Playground.
COMPARING STRATEGIES ON THE SAME TEXT
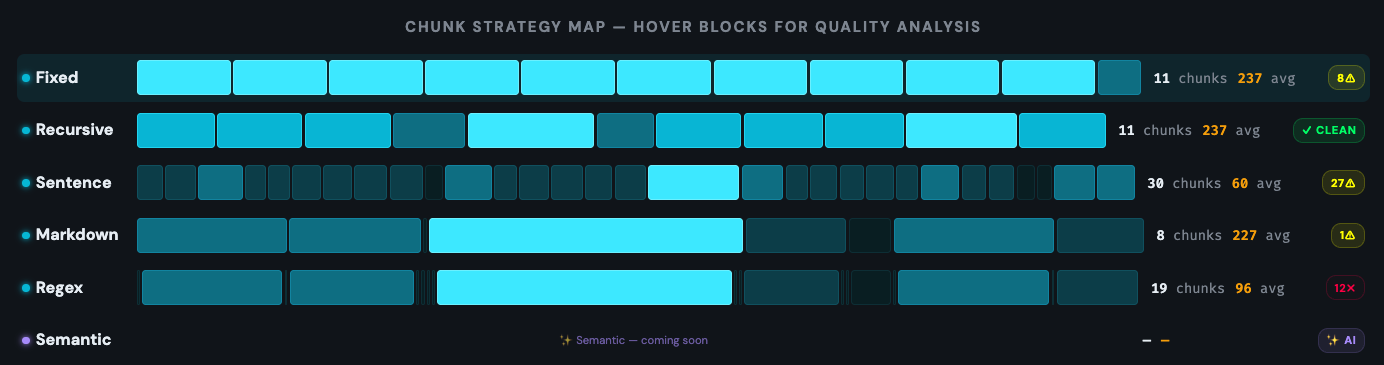
FIXED-SIZE CHUNKING
The most basic approach: split text at exact token or character intervals. You set a chunk size — say 512 tokens — and the splitter cuts at that count regardless of what's in the text. Fast and predictable.
The problem is obvious — it has no awareness of content structure. Sentences get cut mid-word. A paragraph about billing might end mid-sentence and merge with something completely unrelated. Despite this, fixed-size 512-token chunks scored 67% accuracy in the Vecta benchmark — second place overall — because consistent chunk sizes = consistent embeddings.
RECURSIVE CHARACTER SPLITTING
The benchmark winner. Recursive splitting indentifies a handful of separators and repeats — paragraph breaks first, then single new lines, then sentences, then spaces, then individual characters. It always splits at the highest-level that keeps the chunk under your target size.
This means a 512-token chunk will break at a paragraph boundary if possible, fall back to a sentence boundary if the paragraph is too long, and only resort to mid-sentence splits as a last resort. It's why recursive splitting hit 69% accuracy in the Vecta study — it respects natural text structure. Both LangChain and LlamaIndex use variants of this as their primary splitter.
SENTENCE-BASED CHUNKING
Groups a fixed number of complete sentences per chunk. Instead of counting characters or tokens, it identifies sentence endings — periods, question marks, exclamation points — and packs N sentences together.
The advantage is that no sentence ever gets split. The disadvantage is uneven chunk sizes — a chunk of 3 short sentences might be 40 tokens while 3 long sentences could be 300. This unevenness can affect embedding quality since embedding models produce a single fixed-size vector regardless of length.
MARKDOWN / HEADER-BASED CHUNKING
Splits at heading boundaries — H1, H2, H3 — keeping each section as its own chunk. This is structure-aware chunking: it uses the document's own organization rather than imposing radnom cuts.
For well-structured documents, this is extremely effective. Each chunk maps to a single topic the author intended as a unit. The limitation is that it only works when documents actually have meaningful header structure — and sections that are too long still need secondary splitting.
REGEX-BASED CHUNKING
Split on any custom pattern you define. Changelogs with version headers, legal documents with numbered clauses, scientific papers with figure references — any content that is predictable with deliimiters works extremley well.
This is the power-user option. It requires knowing your content's structure well enough to write a pattern, but when you get it right, the chunks are perfectly aligned to your document's natural units.
SEMANTIC CHUNKING
The most sophisticated — and most controversial — approach. Semantic chunking embeds every sentence, measures similarity between adjacent sentences, and splits where the semantic distance exceeds a threshold. The whole idea is to group content by topic.
The controversy comes from the benchmarks. Chroma's research showed semantic chunking achieving 91.9% recall — the highest of any method. But the Vecta benchmark showed it scoring just 54% on end-to-end accuracy, 15 points behind recursive splitting. The explanation: semantic chunking produced fragments averaging only 43 tokens. Those tiny chunks retrieved well in isolation but gave the LLM too little context to generate correct answers.
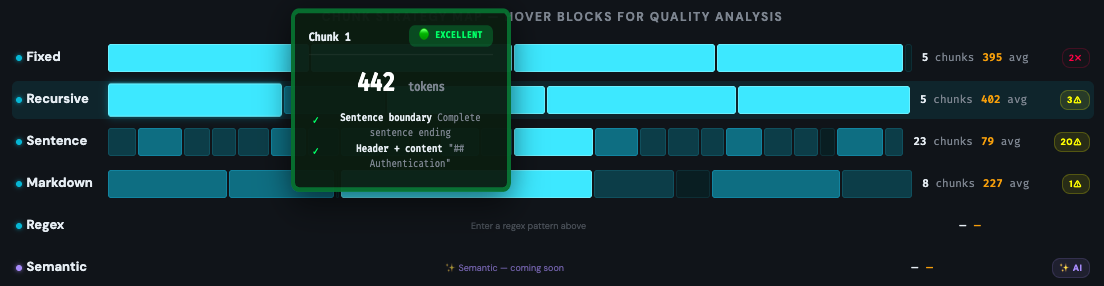
HOW THE PLAYGROUND GRADES YOUR CHUNKS
STRATEGY QUICK REFERENCE
Every claim in this section can be verified in seconds. Paste any document into the RAG Chunking Tool, run all strategies, and compare the results yourself. The strategy map makes the differences impossible to miss.
4Finding the Right Chunk Size
If you search for the best chunk size for RAG, you'll find recommendations ranging from 128 tokens to 2,048. The spread is confusing until you look at the actual benchmark data — which paints a surprisingly consistent picture.
WHAT THE BENCHMARKS SAY
NVIDIA tested chunk sizes from 128 to 2,048 tokens across five datasets including financial documents, academic papers, and general knowledge bases. The pattern was clear: extreme sizes underperformed in both directions. Chunks at 128 tokens were too small — the retriever found fragments but the LLM couldn't generate useful answers from them. Chunks at 2,048 tokens were too large — relevant information got buried in noise. The middle range of 512 to 1,024 tokens consistently performed best, with the optimal size depending on query type.
That query-type dependency matters. Factoid queries — questions asking for a specific name, date, or number — work best with smaller chunks in the 256–512 range. The retriever needs to find a precise answer, and smaller chunks mean less noise around it. Analytical queries — questions requiring explanation, comparison, or multi-step reasoning — need larger chunks in the 512–1,024 range because the LLM needs surrounding context to construct a coherent answer.
If your system handles a mix of both query types, 400–512 tokens is the balanced starting point that multiple independent benchmarks converge on. Microsoft Azure recommends 512 tokens as a default. Arize AI found 300–500 with K=4 retrieval to offer the best speed-quality tradeoff. The Vecta benchmark's winner — recursive splitting at 512 — reinforces this range.
WHAT THE LLM ACTUALLY SEES AT EACH SIZE
payment method
in settings"
Go to Settings › Billing › Update Card.
Enter your new card details and click Save.
Changes take effect immediately."
Enable 2FA...
Reset password...
Delete account...
Invite team members..."
THE OVERLAP QUESTION
Overlap means consecutive chunks share some tokens at their boundaries, so information that falls on a cut point still appears in at least one chunk. The standard recommendation for RAG chunk overlap best practices is 10–20% of your chunk size — for 512-token chunks, that's 50–100 tokens of overlap.
THE NUMBERS TO START WITH
For most teams, the right answer is simpler than expected. The starting configuration below is backed by NVIDIA, Vecta, Microsoft Azure, and Arize AI all independently arriving at the same range.
5 Semantic vs Recursive Chunking
If you've spent any time in RAG communities, you've seen this argument: semantic chunking should be better because it understands meaning, while recursive splitting is just dumb text manipulation. The intuition feels airtight. The benchmarks tell a different story.
WHAT SEMANTIC CHUNKING PROMISES
Semantic chunking embeds every sentence, compares adjacent embeddings for similarity, and cuts where the topic shifts. In theory, this produces chunks perfectly aligned to meaning — no split thoughts, no mixed topics. And on retrieval-only metrics, it delivers. Chroma's research measured semantic chunking at 91.9% recall, the highest of any strategy tested. It genuinely finds relevant text better than simpler methods.
WHAT ACTUALLY HAPPENS END-TO-END
Retrieval is only half the pipeline. The LLM still has to generate a correct answer from the retrieved chunks. The Vecta/FloTorch benchmark tested this end-to-end — and semantic chunking dropped to 54% accuracy, a full 15 points behind recursive splitting at 69%.
The culprit was fragment size. Semantic chunking's topic-detection algorithm created chunks averaging just 43 tokens. Those tiny fragments retrieved cleanly in isolation, but when passed to the LLM, there wasn't enough context to construct a useful answer. High recall, wrong answer.
The Vectara NAACL 2025 study — the only peer-reviewed paper in this comparison — confirmed the pattern: fixed-size chunking outperformed semantic chunking across document retrieval, evidence retrieval, and answer generation on realistic document sets.
WHY RECURSIVE WINS IN PRACTICE
Recursive splitting isn't smarter — it's more predictable. It produces consistent chunk sizes that give the LLM enough context every time. It has zero computational overhead — no embedding calls during chunking. And it respects natural text structure through its separator hierarchy without needing to understand meaning.
The cost difference matters too. Semantic chunking requires embedding every sentence in your corpus during the chunking step itself — before you even start indexing. For a 100,000-document knowledge base, that's a significant API or compute expense just for preprocessing.
WHEN SEMANTIC IS STILL WORTH IT
Semantic chunking isn't dead — it just needs guardrails. If you set a minimum chunk size floor of 200–400 tokens and use it on high-value documents with dense topic transitions — compliance docs, multi-topic research papers, regulatory filings etc... — it can outperform recursive splitting. The key is preventing the trap of fragmentation.
6 Matching Strategy to Document Type
The Vecta benchmark crowned recursive splitting as the overall winner — but that was on academic papers. NVIDIA found page-level chunking won on financial documents. A peer-reviewed clinical study (MDPI Bioengineering, November 2025) found adaptive chunking hit 87% accuracy versus 13% for fixed-size baselines on medical documents — a 74-point gap that was statistically significant, not a fluke.
That gap is what happens when you use the wrong strategy for your document type. The chunking approach that works brilliantly on blog posts can fail on legal contracts. Take the quiz below to get a strategy recommendation tailored to your specific use case.
HOW TO THINK ABOUT IT
Your best chunking strategy depends on three things: your documents, your queries, and your constraints. What type of content are you splitting — structured docs with headers, dense legal filings, or flat blog posts? Are users asking for specific facts or broad explanations? And how much time and budget can you invest in the chunking step itself? The quiz below walks you through 6 quick questions and recommends a specific strategy with a ready-to-use configuration.
FIND YOUR STRATEGY
The flowchart above maps the same logic that the research supports — structure-aware methods for structured docs, size-tuned recursive splitting for everything else. Whatever recommendation you get, you can test it immediately in the Chunking Playground by pasting your own documents and comparing the results.
7 How to Evaluate Your Chunks
Many teams pick a chunking strategy, set the parameters, and never look at the output. They go straight from configuration to embedding to production — and only discover problems when users start complaining about bad answers. The fix is simple: look at your chunks before you ship them.
WHAT TO CHECK
Every chunk should pass three tests:
1. Is it a complete thought? Read the chunk in isolation — if you can't understand what it's about without seeing the surrounding text, the LLM won't be able to either. A chunk that starts with "Additionally, the system also supports..." has lost its flow.
2. Does it mix unrelated topics? A chunk containing billing instructions combined with API settings will confuse both the retriever and the generator. When a user asks about payments, this chunk will match — but half its content is irrelevant noise.
3. Is it the right size? The benchmarks converge on 300–512 tokens for most use cases, but the real test is whether the chunk contains enough information to answer a question about its topic without needing another chunk to fill in the gaps.
GOOD VS BAD CHUNKS — SPOT THE DIFFERENCE
WARNING SIGNS TO WATCH FOR
SEE IT IN ACTION
The Chunking Playground grades every chunk automatically using a green/yellow/red system and flags the exact signals listed above. Instead of reading through hundreds of chunks manually, you can spot problems in seconds.
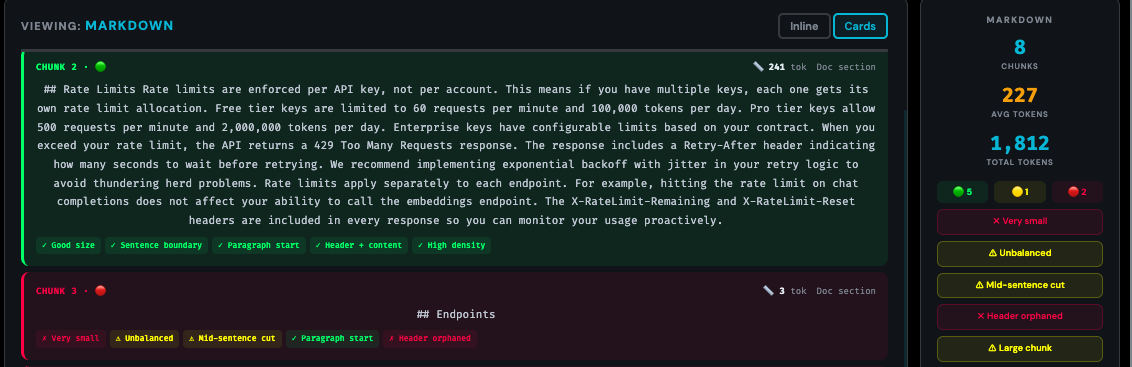
FROM EVALUATION TO ITERATION
The evaluation loop is straightforward: chunk your documents, inspect the output visually, fix the obvious problems — usually by switching strategy or adjusting chunk size — then run a set of representative queries against your chunks to verify retrieval quality. Only after this manual check should you move to automated evaluation with metrics like precision, recall, and faithfulness.
The teams that skip this step and go straight to metrics are optimizing numbers without knowing if the underlying chunks make sense. Automated metrics can tell you retrieval is improving — they can't tell you why a specific chunk is confusing the LLM. Visual inspection can.
8FAQ & Conclusion
Chunking is not a preprocessing detail — it's the foundation your entire RAG system is built on. The benchmarks are clear: recursive character splitting at 512 tokens with 10% overlap is the validated starting point for most use cases. It scored highest in the Vecta/FloTorch study, costs nothing extra to implement, and handles mixed document types gracefully.
But the real insight from 2026's research isn't that one strategy wins everywhere. It's that matching your strategy to your document type matters more than picking the "smartest" approach. Page-level chunking wins on financial PDFs. Markdown splitting wins on structured documentation. Semantic chunking can win on dense cross-referencing content — but only with a minimum size floor. And short, focused content like FAQs shouldn't be chunked at all.
The teams that get chunking right share one habit: they look at their chunks before shipping them. They paste documents into a visualization tool, inspect where the splits fall, check for mid-sentence cuts and orphaned headers, and fix the obvious problems before anything reaches the vector database.
